|
Hey, I am a doctoral student at Computer Vision Group, Tampere University, where I am working with and advised by Prof. Esa Rahtu on audio-visual learning and multi-model machine learning. I have been lucky to work on audio-visual 3D perception and navigation as a visiting researcher in the MARS Lab at Tsinghua University and Shanghai QiZhi Institute, advised by Prof. Hang Zhao. I completed my master thesis at Tampere University of Technology with Prof. Heikki Huttunen on data engineering and signal processing in 2017. Prior to doctoral study, I worked as a researcher at Nokia Technologies till 2019 and was advised by Dr. Tinghuai Wang and Prof. Joni Kamarainen. Contact info:Address: TC 307, Korkeakoulunkatu 7, FI-33720, Tampere, Finland Email: firstname.lastname(at)tuni(dot)fi
|

|
|
I have a broad interest in computer vision with a focus on audio-visual learning, multi-model machine learning, 3D perception, embodied AI navigation, and semantic segmentation. Recent published papers are presented as follows. |
|
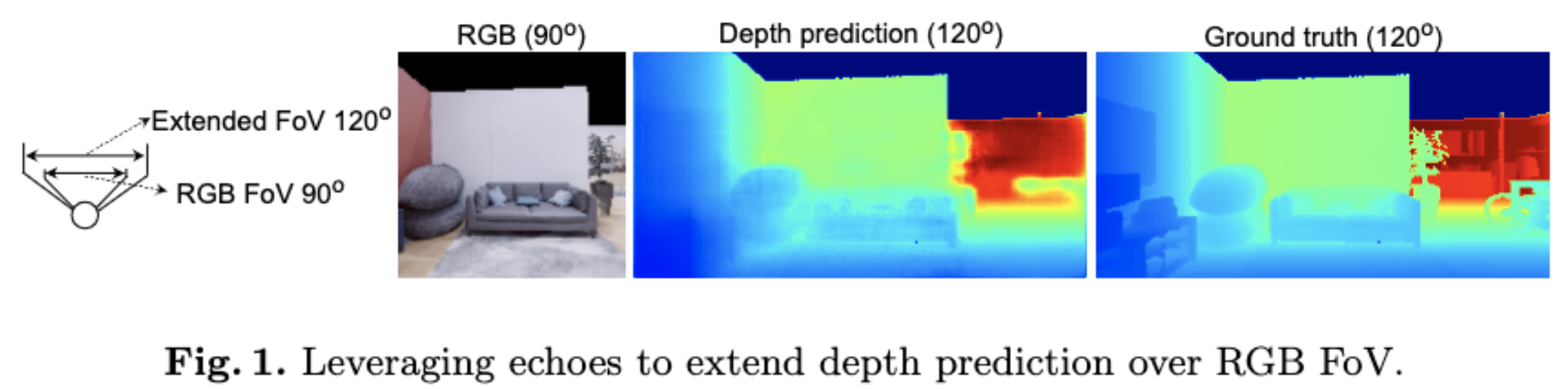
Lingyu Zhu, Esa Rahtu, Hang Zhao Project | Paper In this paper, we perform depth estimation by fusing RGB image with echoes, received from multiple orientations. Unlike previous works, we go beyond the field of view of the RGB and estimate dense depth maps for substantially larger parts of the environment. We show that the echoes provide holistic and in-expensive information about the 3D structures complementing the RGB image. Moreover, we study how echoes and the wide field-of-view depth maps can be utilised in robot navigation. |
|
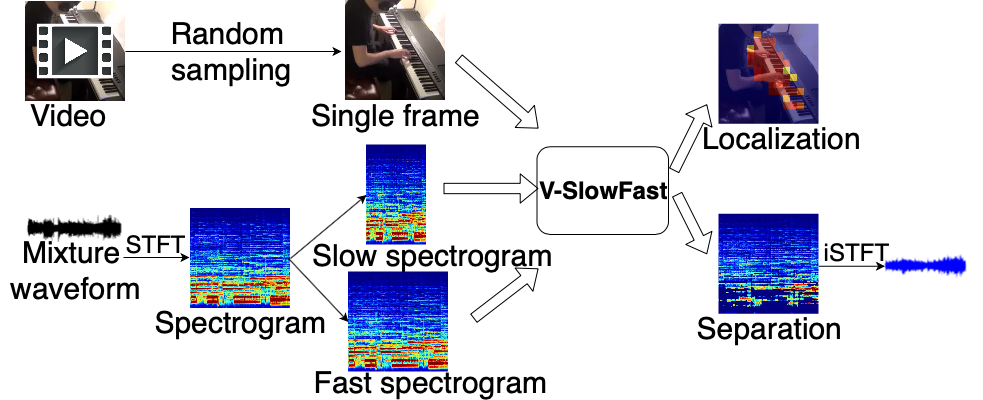
Lingyu Zhu, Esa Rahtu Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022 Project | Paper In this paper, we propose a new light yet efficient three-stream framework V-SlowFast that operates on Visual frame, Slow spectrogram, and Fast spectrogram for visual sound separation. The Slow spectrogram captures the coarse temporal resolution while the Fast spectrogram contains the fine-grained temporal resolution. |
|
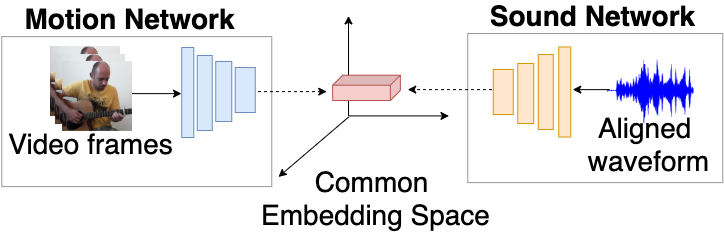
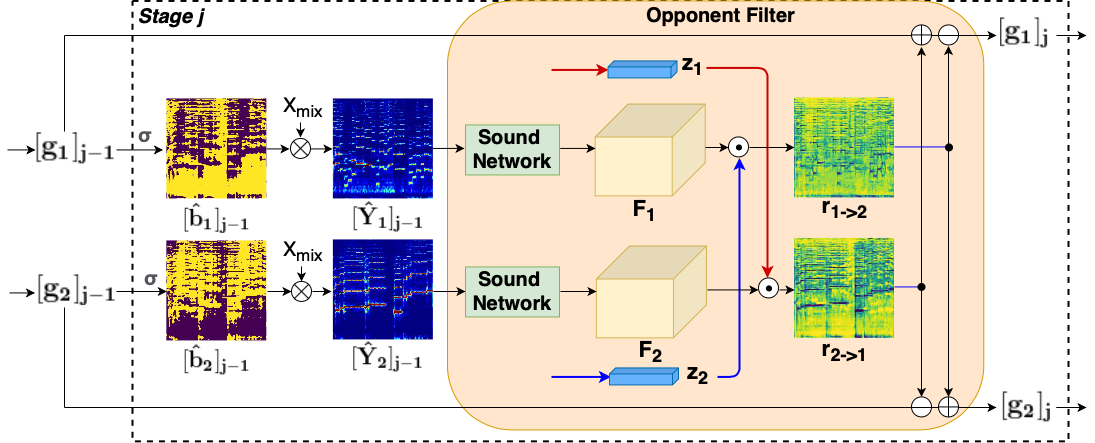
Lingyu Zhu, Esa Rahtu Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022 Project | Paper | Code In this paper, we introduce a two-stage visual sound source separation architecture, called Appearance and Motion network (AMnet), where the stages specialise to appearance and motion cues, respectively. We propose an Audio-Motion Embedding (AME) framework to learn the motions of sounds in a self-supervised manner. Furthermore, we design a new Audio-Motion Transformer (AMT) module to facilitate the fusion of audio and motion cues. |

|
Lingyu Zhu, Esa Rahtu European Workshop on Visual Information Processing (EUVIP), 2021 (Best Paper Award) Project | Paper | Code We study simple yet efficient models for visual sound separation using only a single video frame. Furthermore, our models are able to exploit the information of the sound source category in the separation process. To this end, we propose two models where we assume that i) the category labels are available at the training time, or ii) we know if the training sample pairs are from the same or different category. |
|
Lingyu Zhu, Esa Rahtu Asian Conference on Computer Vision (ACCV), 2020 (Oral Presentation) Project | Paper | Code We present a system for efficient refining sound separation based on appearance and motion information of all sound sources, and localizing sound sources at pixel level. |

|
Lingyu Zhu*, Tinghuai Wang*, Emre Aksu, Joni-Kristian Kamarainen Proceedings of the IEEE International Conference on Computer Vision Workshops, 2019 Project | Paper By integrating the cross-granularity contour enhancement into the cross-granularity categorical attention, we achieve better semantic coherence and boundary delineation. |

|
Lingyu Zhu*, Tinghuai Wang*, Emre Aksu, Joni-Kristian Kamarainen 2019 IEEE International Conference on Multimedia and Expo (ICME), 2019 Project | Paper We propose an efficient non-parametric affinity model to achieve efficient instance segmentation on mobile devices. |
|
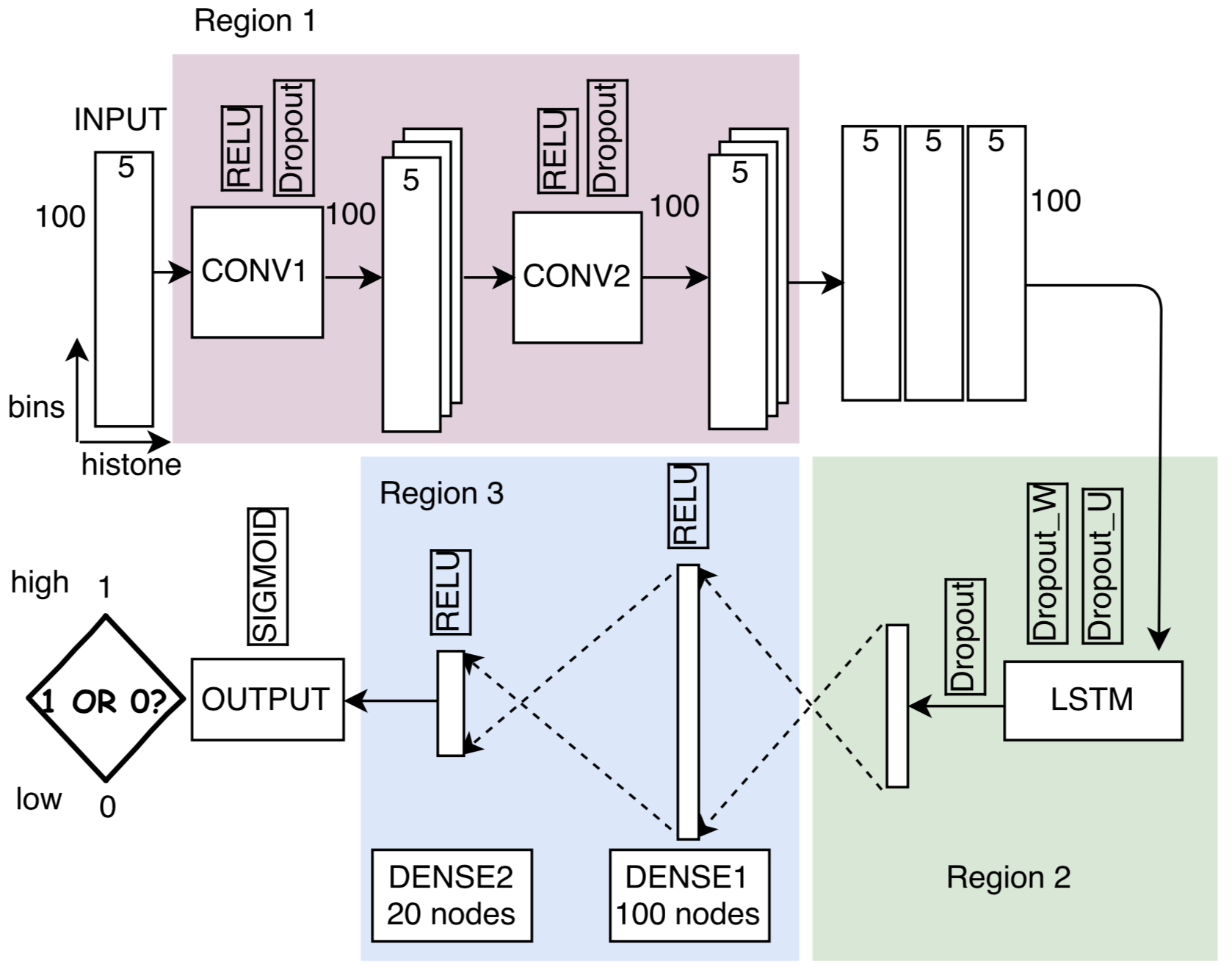
Lingyu Zhu, Juha Kesseli, Matti Nykter, Heikki Huttunen EMBEC & NBC, 2017 Project | Paper | Code This paper studies how a Convolutional Recurrent Neural Network performs on predicting the gene expression levels from histone modification signals. |
|
[Tampere University of Technology] SGN-41007 Pattern Recognition and Machine Learning (Teaching Assistant) [Tampere University of Technology] SGN-84007 Introduction to Matlab (Teaching Assistant) |
|
[Junction 2017, Helsinki, Finland] 1st place from the FleetBoard challenge provided by Daimler [Kaggle competition: Gene Expression Prediction] Organizer of the Kaggle competition [Kaggle competition: TUT Copper Analysis Challenge] 3rd place in this Kaggle challenge [Kaggle competition: TUGraz-TUT Face Verification Challenge] 3rd place in this Kaggle challenge |
|
Template link. |